
Gemini 2.5 Pro Dominates Complex SQL Generation Task (vs Claude 3.7, Llama 4 Maverick, OpenAI O3-Mini, etc.)
How Gemini 2.5 Pro Excels in Complex SQL Generation
Hello, fellow technology enthusiasts!
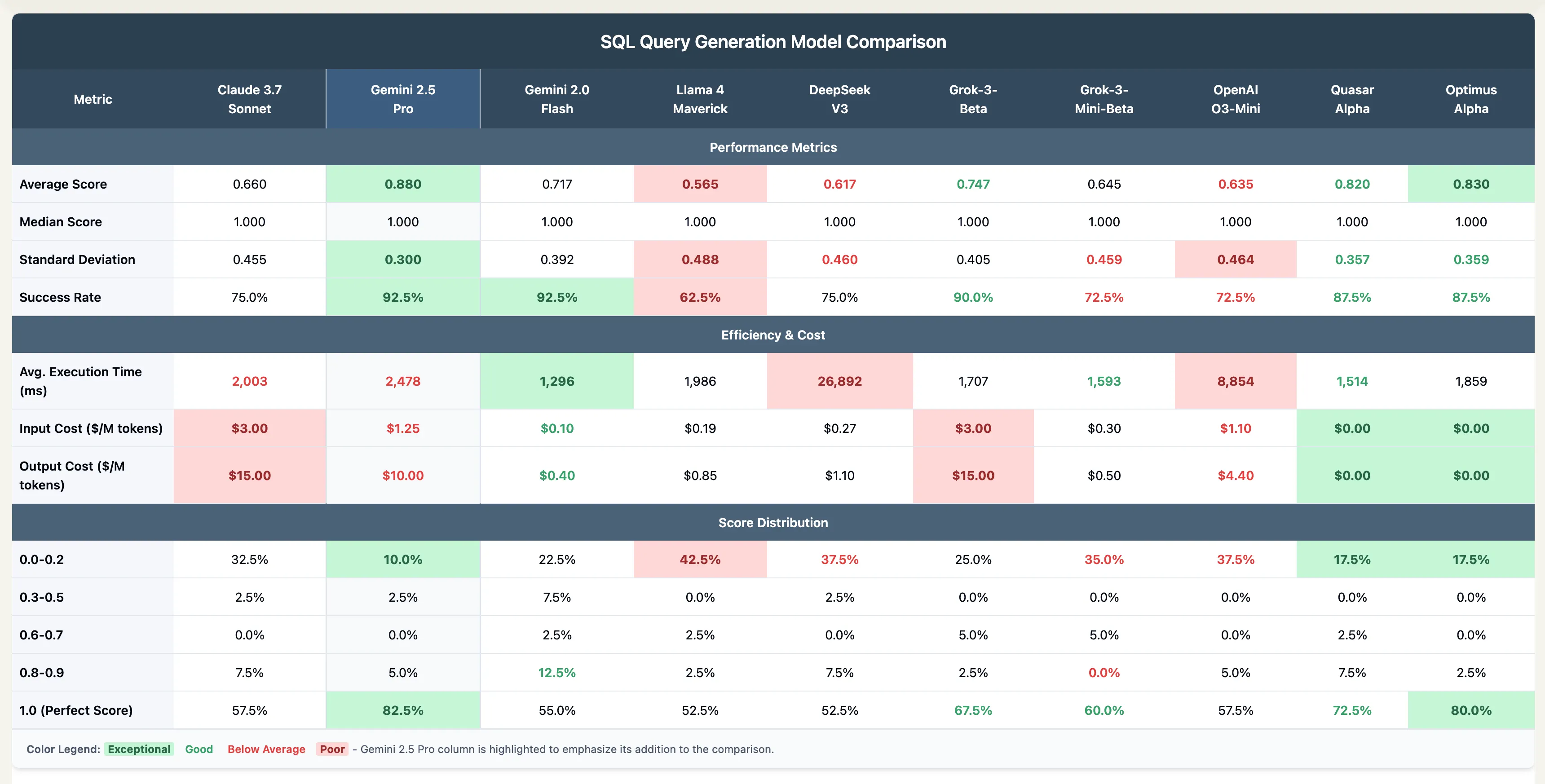
Today, I’m excited to share some illuminating benchmark findings that showcase the capabilities of Gemini 2.5 Pro in generating complex SQL queries. My testing utilized the open-source framework EvaluateGPT, where I compared the performance of ten different language models (LLMs) in crafting SQL queries designed for time-series data analysis.
Testing Overview
The testing process involved several key steps:
- I prompted various LLMs, including Gemini 2.5 Pro, Claude 3.7 Sonnet, and Llama 4 Maverick, to generate specific SQL queries.
- Each generated query was executed against a real database to assess its accuracy and functionality.
- The quality of each SQL query was evaluated using Claude 3.7 Sonnet as a neutral judge, assigning scores from 0.0 to 1.0 based on the original prompt, the generated query, and the results obtained.
- Notably, this was a strict one-shot test without the opportunity for second chances or corrections in code.
Remarkable Results
The findings reveal that Gemini 2.5 Pro significantly outperformed all other models tested when it came to generating accurate and executable SQL queries on the first attempt.
Performance Metrics
| Metric | Claude 3.7 Sonnet | Gemini 2.5 Pro | Gemini 2.0 Flash | Llama 4 Maverick | OpenAI O3-Mini |
|:——-|:——————|:——————-|:——————|:——————|:—————|
| Average Score | 0.660 | 0.880 🟢+ | 0.717 | 0.565 🔴+ | 0.635 🔴 |
| Median Score | 1.000 | 1.000 | 1.000 | 1.000 | 1.000 |
| Standard Deviation | 0.455 | 0.300 🟢+ | 0.392 | 0.488 🔴+ | 0.464 🔴+ |
| Success Rate |













Post Comment